
Songhua Liu
Shanghai, Xuhui District, No. 1954 Huashan Road, School of Artificial Intelligence 211
About Me
I am an assistant professor, Ph.D. advisor at the School of Artificial Intelligence, Shanghai Jiao Tong University. I obtained my Ph.D. at the Department of Electronic and Computer Engineering, National University of Singapore in June 2025, supervised by Prof. Xinchao Wang. Before that, I received my bachelor’s degree in the Department of Computer Science and Technology from Nanjing University in 2021. I was also fortunate to work as a research intern at Rutgers University under the supervision of Prof. Hao Wang and at Baidu Inc. under the supervision of Tianwei Lin.
My research interests include generative AI, especially efficient deep learning driven by synthetic data.. Currently, I am creating Go-There Lab and recruiting Postdocs (1 position available currently), Ph.D. students (2~3 every year starting from fall 2027), Master students (1~2 every year starting from fall 2027), and multiple research interns. If you are interested in working with me at Shanghai Jiao Tong University on the following topics:
- Generative AI: Principle and Architecture;
- Broad Topics and Applications in AIGC;
- Deep Learning driven by Synthetic Data;
feel free to reach out via liusonghua{AT}sjtu.edu.cn. We are always looking for self-motivated students actively.
Currently, I have run out of Ph.D. positions for 2026.
News
Last Update: 2025.12.15
[2025.12] 🔥We release EditMGT, an instructional image editor based on Masked Generative Transformer (MGT). It adaptively localizes editing region during generation and achieves competitive results to state-of-the-art diffusion models with less than 1B parameters. [Page] [Codes] [Dataset]
[2025.11] 🔥We release ViBT. It’s the first time that bridge models are scaled to 20B models, which brings new opportunities for vision-to-vision translation tasks, e.g., image/video editing, controllable image/video generation, etc. [Page] [Codes] [Demo]
[2025.11] 🔥We release FreeSwim, a training-free method that generates 4K-scale videos! Codes are available here.
[2025.11] 🔥FreLay, a stronger extension of WinWinLay, is accepted by AAAI 2026!🎉
[2025.09] 🔥2 papers are accepted by NeurIPS 2025! Congratulations to Ms. Yujia Hu for having her first research work accepted!🎉
[2025.06] 🔥We release WinWinLay, a training-free layout-to-image method that advances both worlds of precision and realism.
[2025.06] 🔥3 papers are accepted by ICCV 2025, including one oral presentation! Congratulations to Ms. Ruonan Yu and all co-authors!🎉
[2025.05] 🔥We release IEAP: Your Free GPT-4o Image Editor. It decouples a complex image editing instruction into several programmable atomic operations and achieves compelling performance! Codes are available here!🚀 Demo is available here.🤗
[2025.05] 🔥We release LLaVA-Meteor, a novel, efficient, and promising method to process visual tokens in VLM.
[2025.05] Congratulations to Mr. Xinhao Tan for having his work accepted at ACL 2025 during his undergraduate period!🎉
[2025.05] 🔥2 papers are accepted by ICML 2025! Congratulations to all co-authors!🎉
[2025.04] 🔥We release Flash Sculptor, an efficient and scalable solution to reconstruct a complex and compositional 3D scene from merely a single image! Try it here🚀
[2025.03] 🔥We release URAE: Your Free FLUX Pro Ultra. It adapts pre-trained diffusion transformers like FLUX to 4K resolution with merely 3K training samples! Codes are available here!🚀 Demos are available here and here.🤗
[2025.03] 🔥We release OminiControl2! OminiControl1 has achieved impressive results on controllable generation. Now, OminiControl2 makes it efficient as well!
[2025.03] 🔥We release CFM! Spectral Filtering provides dataset distillation with a unified perspective!
[2025.02] 🔥3 papers are accepted by CVPR 2025! Congratulations to all co-authors!🎉
[2025.02] 🔥We release a benchmark for large-scale dataset compression here. Try it here!🚀
[2024.12] 🔥We release CLEAR, a simple-yet-effective strategy to linearize the complexity of pre-trained diffusion transformers, such as FLUX and SD3. Try it here!🚀
[2024.12] 🔥We release OminiControl, a minimal yet powerful universal control framework for Diffusion Transformer models like FLUX. Try it here!🚀
Selected Publications and Preprints
-
* Equal Contribution
-
-
Please refer to Google Scholar for the full list.
-
 NeurIPS25
NeurIPS25
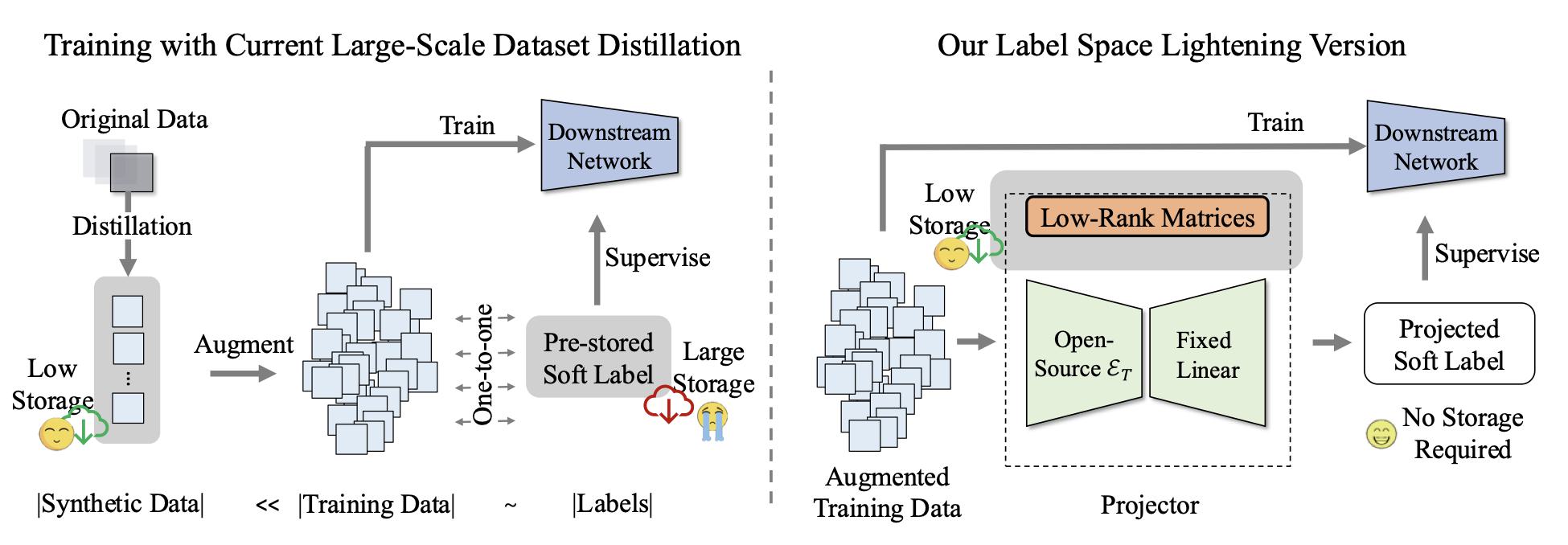 ICCV25
ICCV 2025 OralSynthetic Data for Data Efficiency
ICCV25
ICCV 2025 OralSynthetic Data for Data Efficiency
 ICML25
ICML25
 ICCV25
ICCV25
 NeurIPS25
NeurIPS25
 arXiv24
arXiv24
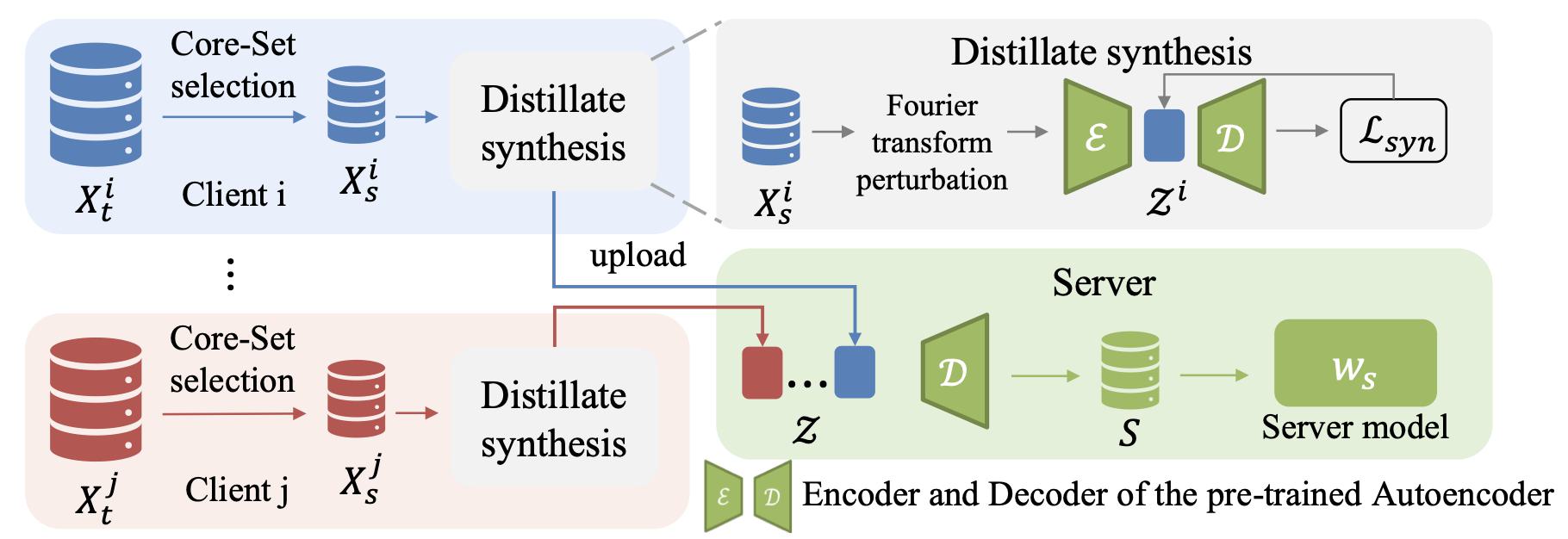 NeurIPS24
NeurIPS24
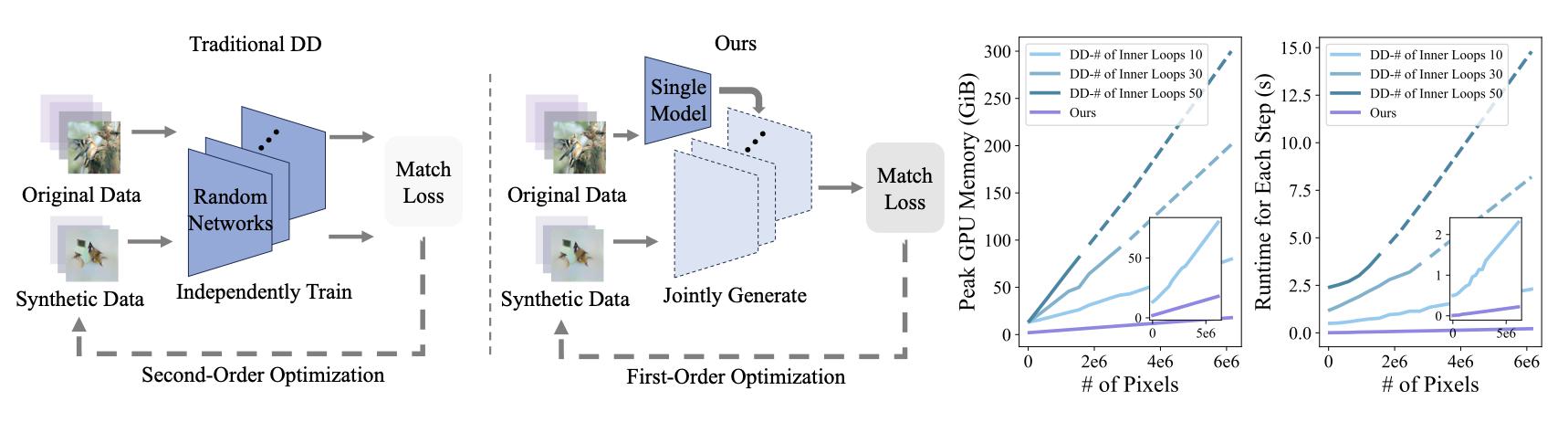 ECCV24
ECCV 2024Synthetic Data for Data Efficiency
ECCV24
ECCV 2024Synthetic Data for Data Efficiency
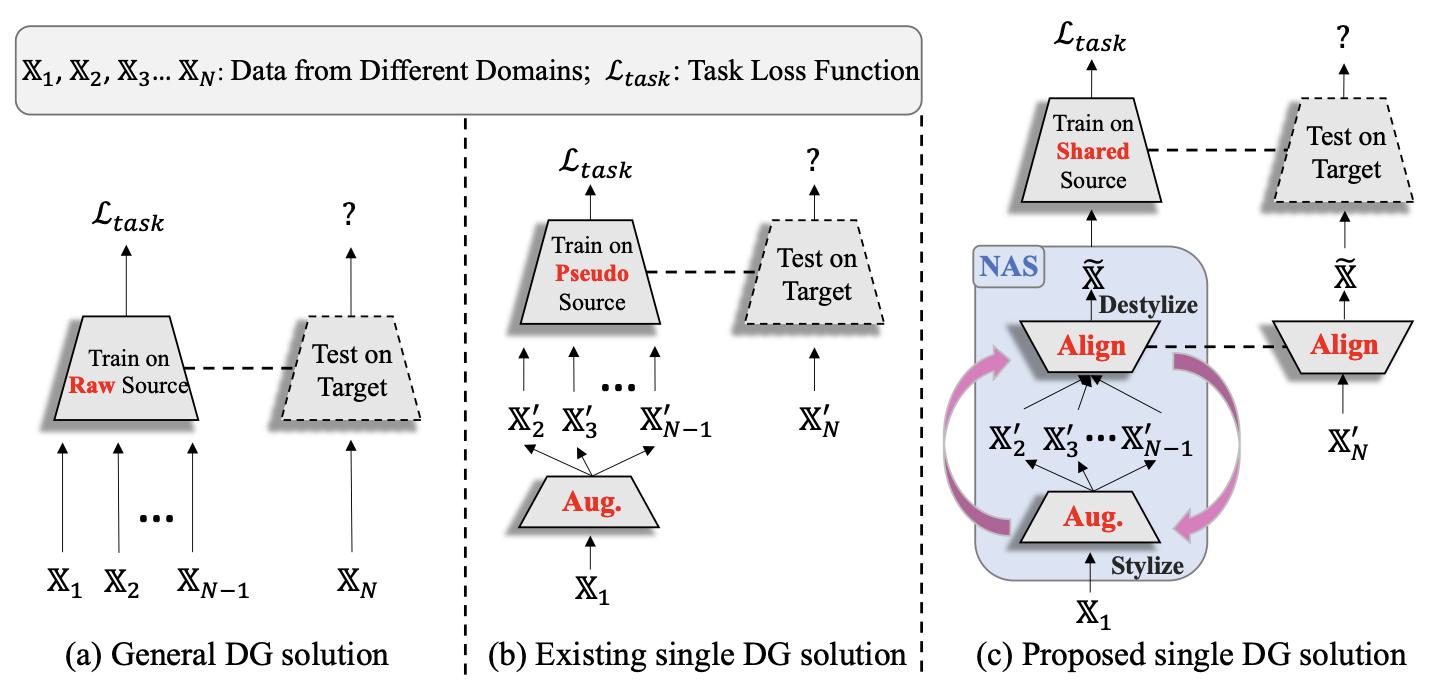 ICML24
ICML24
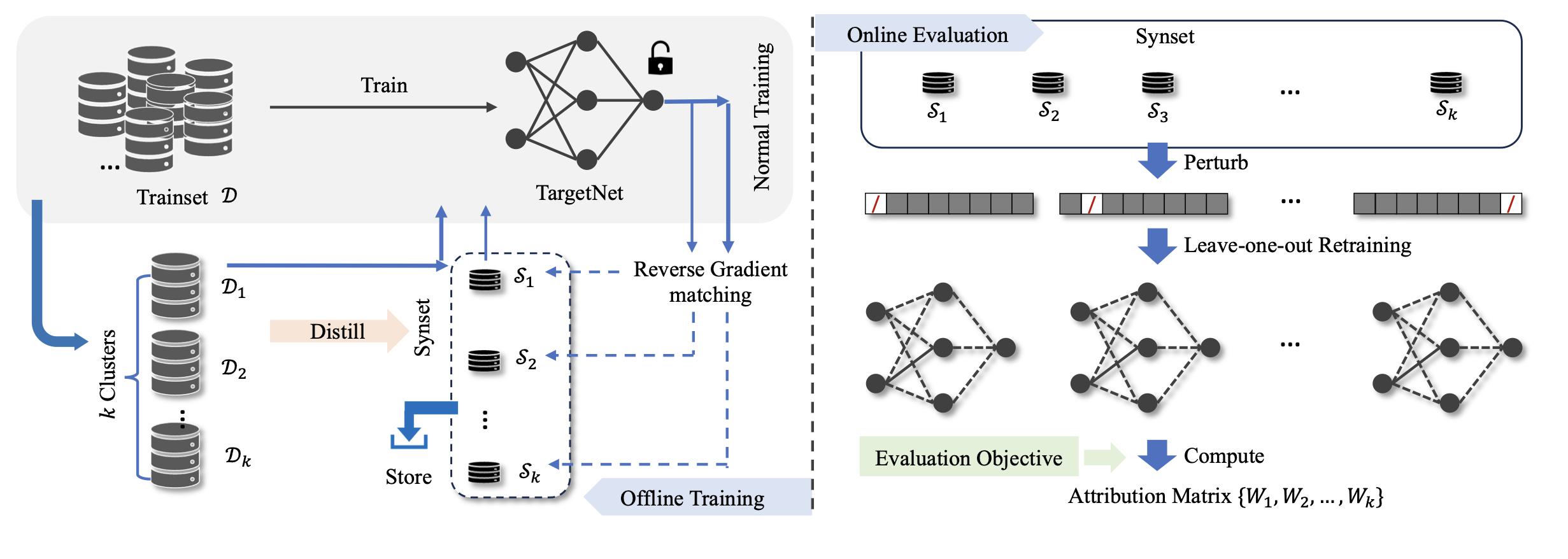 CVPR24
CVPR 2024Synthetic Data for Safety
CVPR24
CVPR 2024Synthetic Data for Safety
 CVPR24
CVPR24
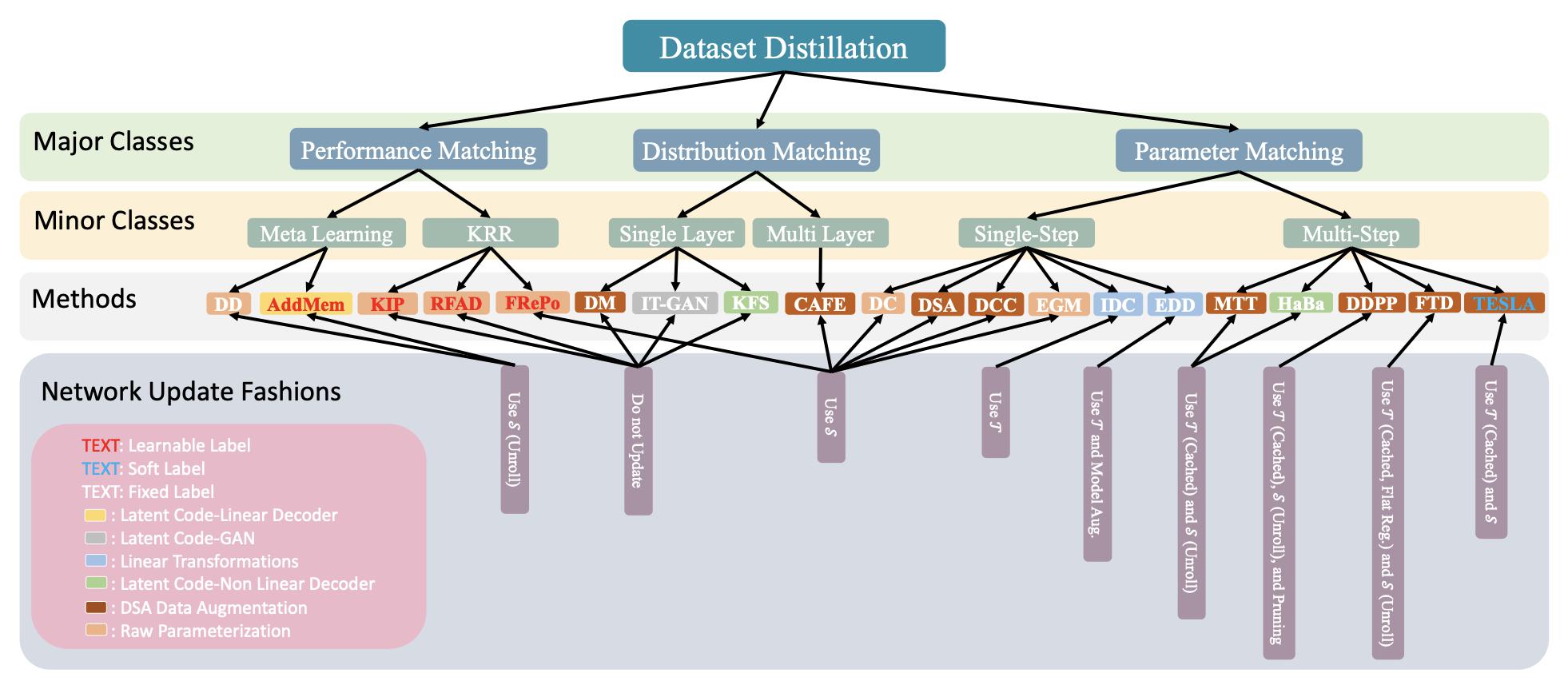 TPAMI23
TPAMI 2023Synthetic Data for Data Efficiency
TPAMI23
TPAMI 2023Synthetic Data for Data Efficiency
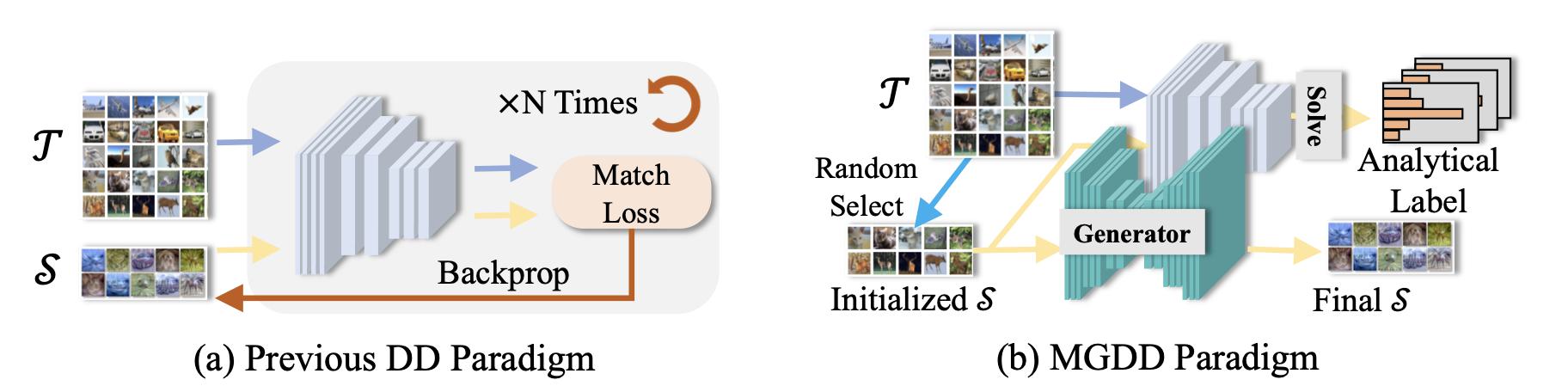 NeurIPS23
NeurIPS 2023 SpotlightSynthetic Data for Data Efficiency
NeurIPS23
NeurIPS 2023 SpotlightSynthetic Data for Data Efficiency
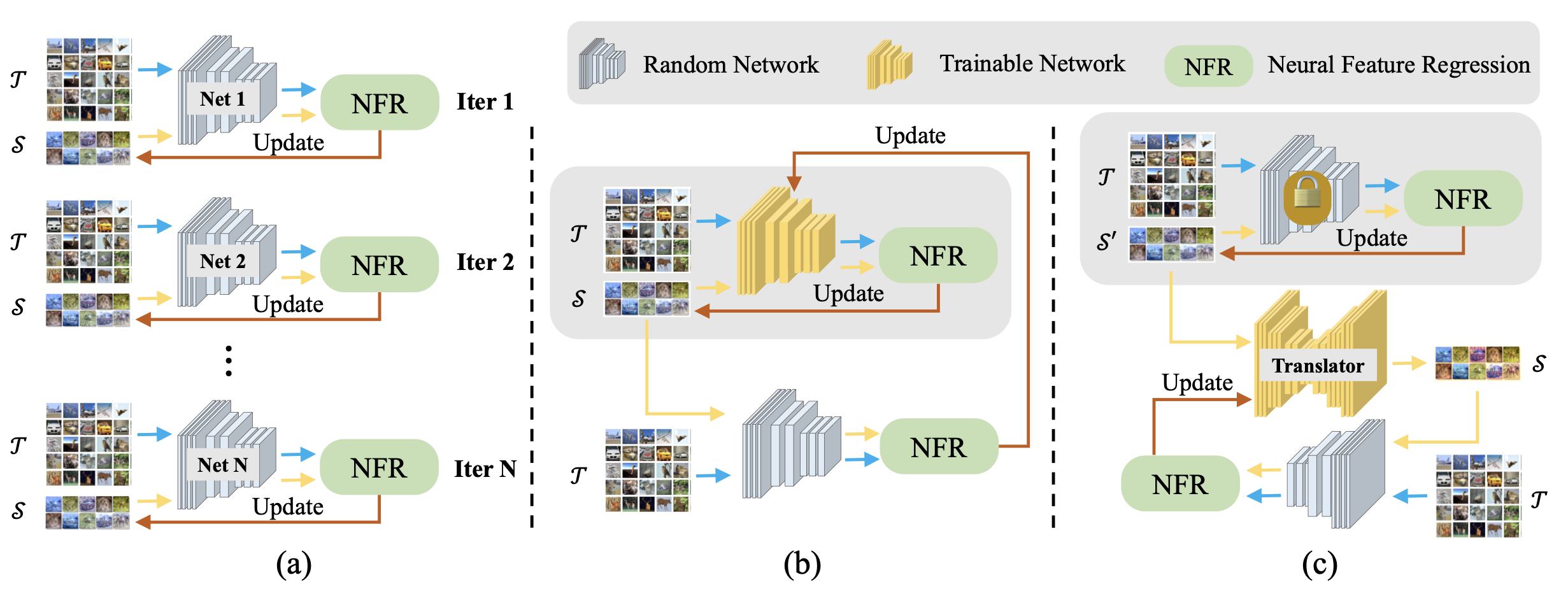 ICCV23
ICCV 2023Synthetic Data for Data Efficiency
ICCV23
ICCV 2023Synthetic Data for Data Efficiency
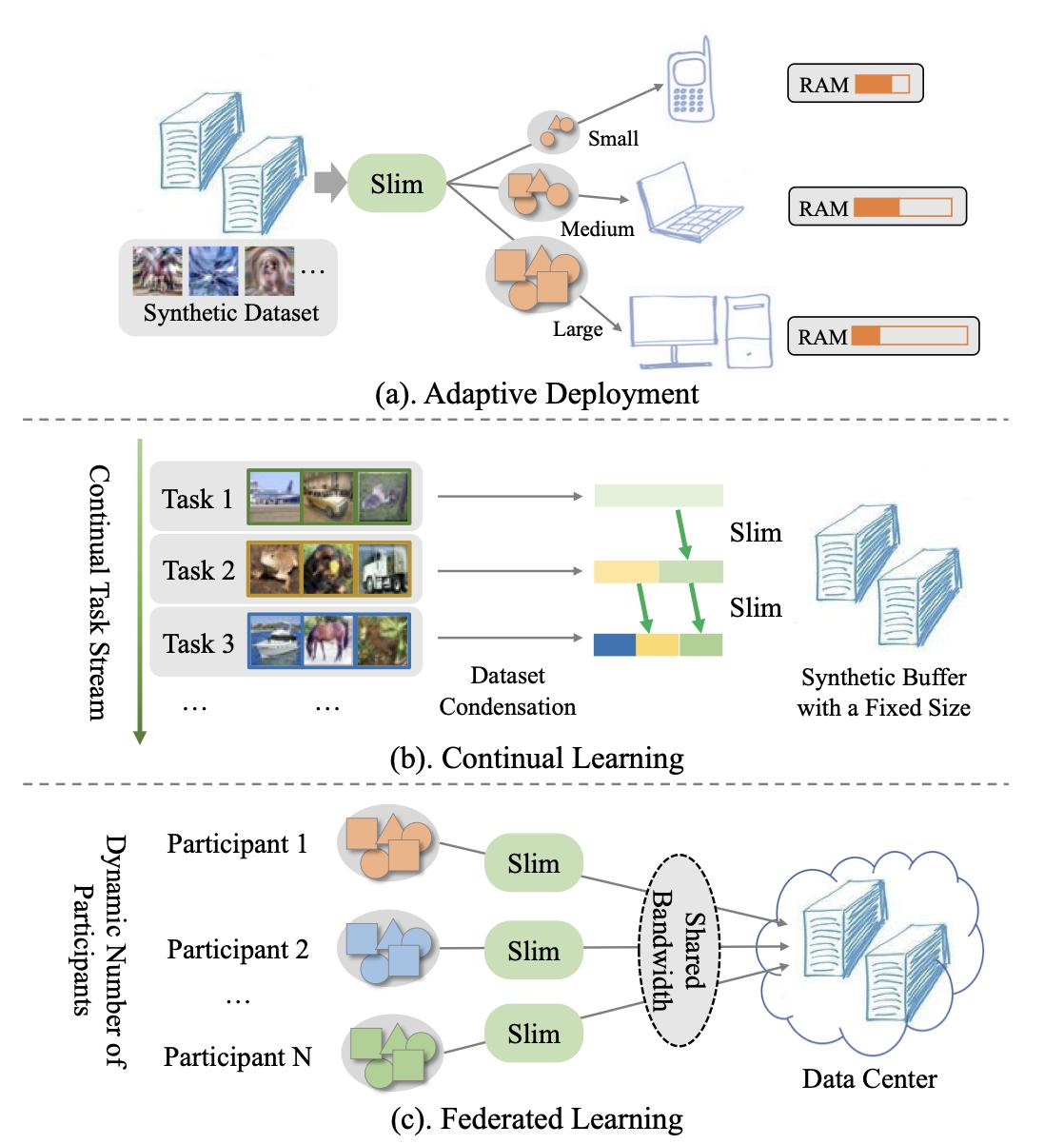 CVPR23
CVPR 2023 HighlightSynthetic Data for Data Efficiency
CVPR23
CVPR 2023 HighlightSynthetic Data for Data Efficiency
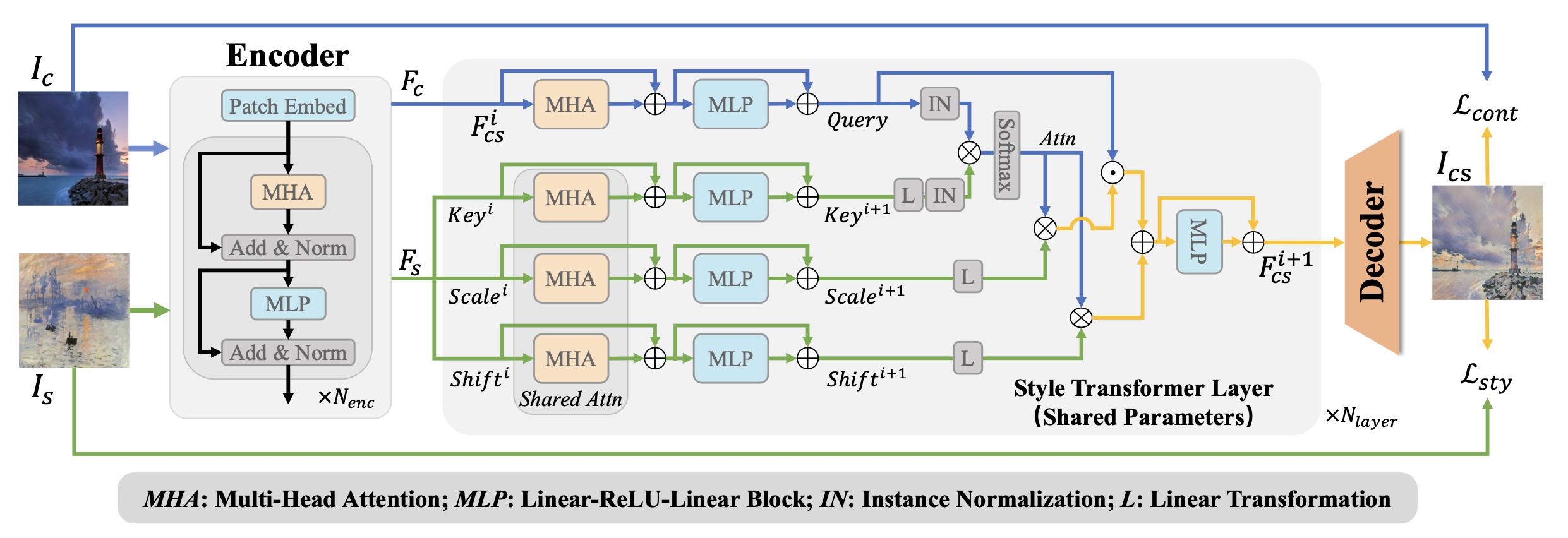 CVPR23
CVPR 2023Visual Synthesis
CVPR23
CVPR 2023Visual Synthesis
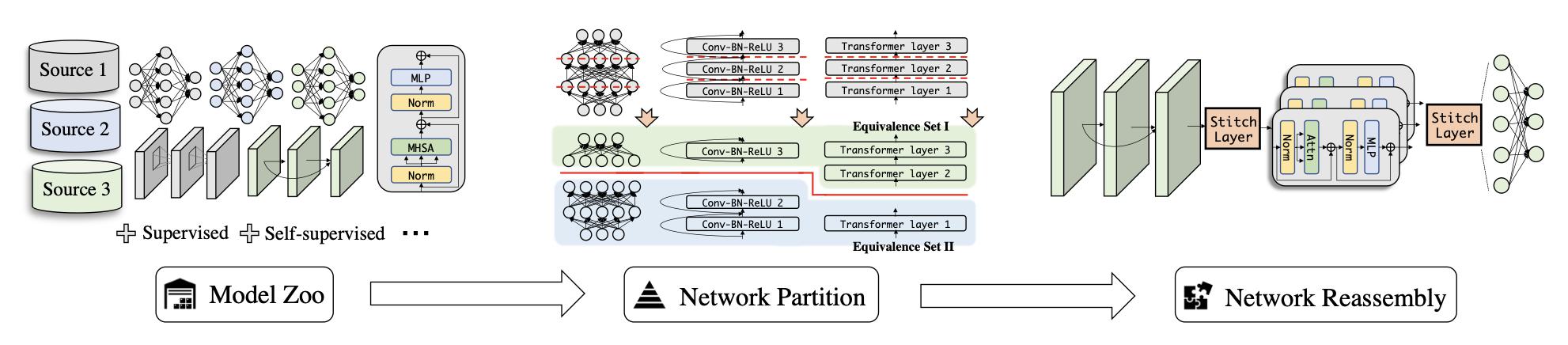 NeurIPS22
NeurIPS22
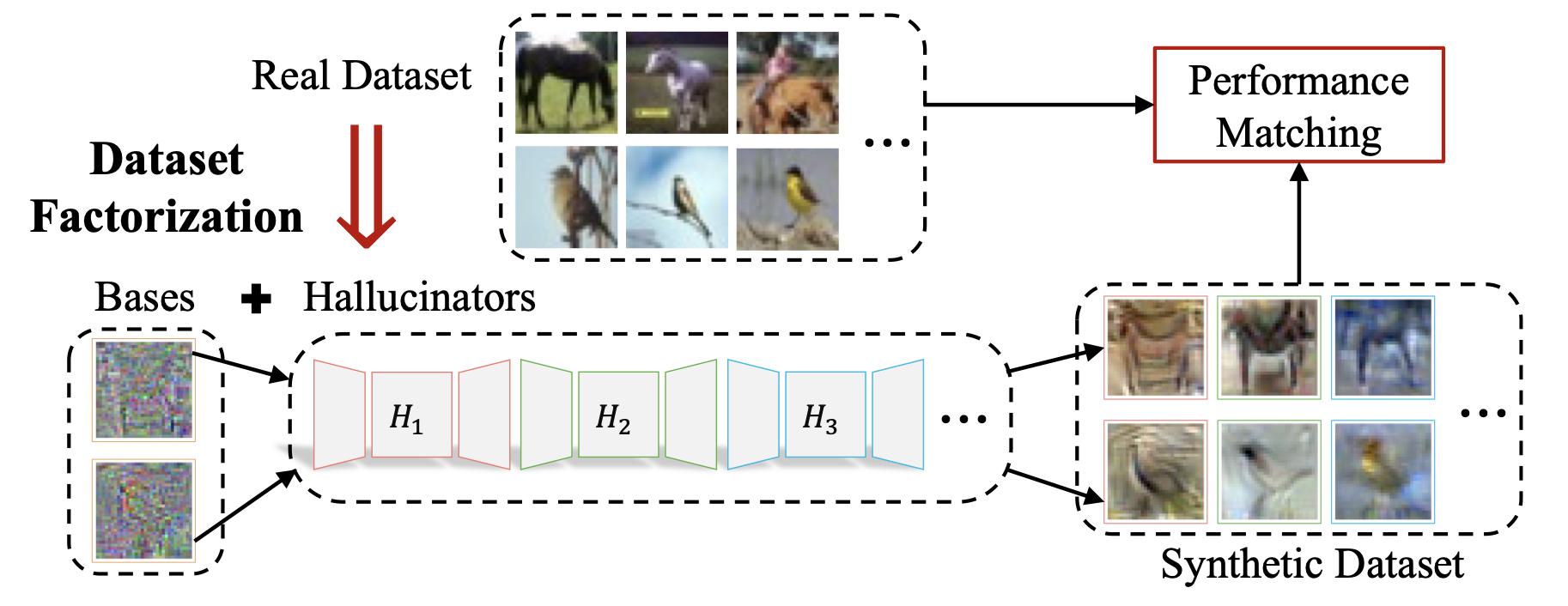 NeurIPS22
NeurIPS22
 ECCV22
ECCV22
 ICCV21
ICCV21
 ICCV21
ICCV21
 MM20
MM20
-